question:为啥不直接写一颗可以存根节点的树(TreeMap)呢,为什么专门写并查集呢
定义
并查集是一种树型的数据结构,可以用链表和数组或树实现。
在并查集(Disjoint Set)中只需要有三个方法init、union和isSameSet
init:把每个点所在集合初始化为其自身)
union(a,b):合并a、b所在的两个集合。
isSameSet(a,b):检查a、b是否在同一集合中。
注意:
思考
我们来看一下之前所学的数据结构是否能完成上面union和isSameset
存有头尾节点的链表:
- uniond的时间复杂度为O(1),使用getFirst和getLast就可完成。
- isSameSet的时间复杂度为O(N),使用contains(需要遍历)。
哈希表:
- union的时间复杂度为O(N),需要扩容resize。
- isSameSet的时间复杂度为O(N),使用contains。
可以发现我们学过的数据结构都能完成这两个操作,但是速度方面则不尽人意,因为他们中的操作中或多或少需要遍历(如链表的contains,哈希表的resize)。
接下来我们看下树怎么样,树该如何判断是同一个集合呢,很简单只要判断是否为同一个根节点即可,然而
正常的树通常会通过根节点找到指定节点,这里我们把树的指向方向倒置,这样就可以通过指定节点找到根节点了。
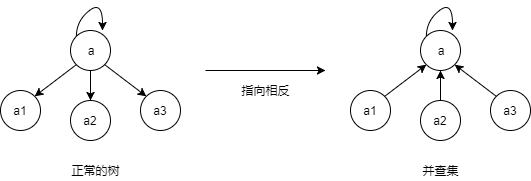
指向方向倒置
再来看看那两个操作是否可行
- union:b的根节点连上a的根接点即可。
- isSameSet:通过对比两个元素的根节点是否相同判断。
因为树查询节点的操作只需要O(logN),并且这两个操作都需要查询根节点,所以树的时间复杂度应该会比前面两个低。其实我们还可以进一步优化,如下:
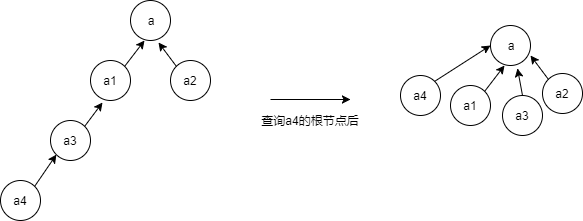
在查询根节点的同时把经过的节点全部直接连到根节点上
关于时间复杂度的问题,由于证明过于复杂此处省略,并直接给出以下结论:
- 查询次数+合并次数大于O(N)以上的时候,单次查询或合并的时间复杂度为O(1)
由此可见并查集是一种特殊的树结构,接下来我们来具体的实现它吧。
TODO:并查集和二叉树(getFirst)有啥区别
实现
下面给出两种实现方式,一种通过哈希表,一种通过数组
1 | //哈希表 |