预热
首先我们要简单了解几个概念,详细的可以看下https://www.cnblogs.com/xzwblog/p/7255364.html和https://blog.csdn.net/moakun/article/details/80688976。
下面我抽出几点粗略看一下:
集群:同一个业务,部署在多个服务器上,集群分几种,负载均衡集群也是其中一种。
分布式:一个业务分拆成多个子业务,或者本身就是不同的业务,部署在不同的服务器上。
简单说,分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率。
负载均衡:在请求和我们真正的服务器之间再加一层负载均衡器(管理者),请求会发送到均衡器,再由均衡器把请求按特定算法转发给集群中某一台机器。这样就实现负载的均衡了。
这里是我自己写的,嘻嘻^_^
上面的知识点有了大概的认识后,我们接下来看看下面的问题:
- 假设前端有n台机器提供同一个搜索或录入功能,而后端有一个集群,而集群中有3台机器。
功能的流程是这样的:前端的机器都有一个hash(),得到code后mod 3决定存在哪台机器。
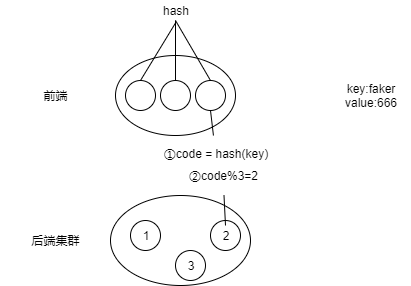
如图所示,这就是经典的负载均衡。
然而要对集群加减机器的时候,就会有个严重的问题,原本均衡存储在3台机器上的数据,要重新求hashCode并存入。这样数据迁移的要求十分的高。这时候就可以用到一致性哈希算法了。
一致性哈希算法
一致性哈希算法可以在增\删集群(节点)的时候需要重新hash的数量减少、还能保证负载均衡。知道作用后,来看看大致的思路吧。
- 把hash()后的值当成环型,假设范围为0-2^64,现在有3台机器m1、m2、m3,取他们的唯一标识符(ip或mac之类的)进行hash(),这样3台机器就分布上环中了
值得注意的是hash()后不需要mod。
- 录入和读取数据的时候,同样hash,并在环上顺时针寻找最近的机器进行操作。
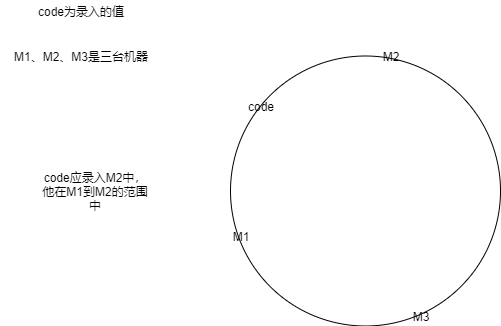
再具体点怎么操作呢,把m1、m2、m3的hash值排序并存放为数组,再放在前端(负载均衡器)中,而后,用二分的方式求出数组中第一个大于等于hashcode(前端传来的)的位置,就找到最近的哪台机器了。
优点
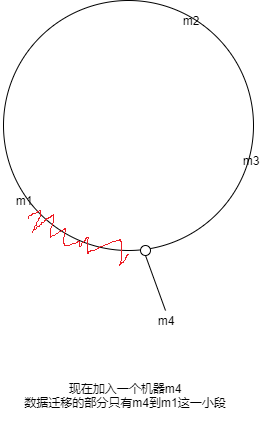
缺点
机器数量少时,环并不能保住均分,因为hash要均分的条件是要一定数量上的。
加\减机器的时候,环的分布均衡也被破坏了
解决方案-虚拟节点
给每台机器m都分配1000个节点,并拥有路由表。
让节点均衡的分布在环上,只要找到对应节点就存在对应的机器上。
这样你删改机器、他们只是比例变了,但仍是均衡的(每台1000)。