施工中。待补充有TODO字眼,记得c+f去补充
//如需要复习sql语句,请直接搜索表的定义
-本文的DDL文件和数据文件均可在https://www.db-book.com/db7/index.html下载。
第一章:概述数据库
数据库:
长期存储在计算机内,有组织的可共享的数据集合。数据库管理系统:
数据库 + 一组用以访问、更新和管理这些数据的程序DBMS的特性:
数据访问的高效和可扩展性
缩短应用开发时间
数据独立性(物理数据独立性/逻辑数据独立性)
数据完整性和安全性
并发访问和鲁棒性数据抽象
数据库系统隐藏了数据在存储、维护方面的细节,以视图的形式为普通用户提供数据。数据库系统必须能满足高效地查询数据的需求,为此设计者将数据库系统抽象为三层,给不同用户使用:物理层、逻辑层、视图层{% asset_img dataAbstract.png %}物理层:描述数据实际的存储方式
逻辑层:描述数据库中存储什么数据以及数据间的关系
视图层:应用程序能够隐藏数据类型的详细信息,视图也可以出于安全目的隐藏数据(如:银行app,总金额)
数据模型(data model)
根据数据抽象的不同层次使用不同的数据模型进行描述,常见的有:实体-关系模型、关系模型、面向对象模型等。实例与模式
数据模式(schema):数据库的总体设计,类似于变量的类型信息,分为物理模式(物理层)、逻辑模式(逻辑层)
实例(instance):数据库中信息的集合,类似于变量的值
*个人理解:有模式才可以创建实例*
{% asset_img 三层模型.png %}
> 三层模型,可以相互转换,如视图层的外模式可以通过,外模式/模式映射转换为模式(逻辑层 )数据模式(schema)与数据模型(model)与数据抽象的关系
数据抽象:是将数据抽象化、逻辑化,是对数据的抽取过程。(数据库不同的用户需要不同层次的抽象)
数据模型:是对数据进行一致性约束的概念工具的集合(此处应该是形如关系模型中的关系、关系模式、实例等),主要使用逻辑概念来表示数据。
数据模式:利用数据模型组织抽取的数据所得的结果,也即是数据抽象的结果
三者之间的关系:
数据抽取作为总的过程,利用数据模型,对现实具体系统的数据进行抽取,组织,使其具有结构化的特征,最终得到的结果,即是数据模式。事务 (transaction):一个操作的集合
原子性(automicity):要么全部完成,要么全部不完成。
一致性(consistency):如a和b转账,转完后a和b余额之和是保持不变的。
隔离性(isolation):TODO
持久性(durability):操作全成功后,即使发生系统故障,数据仍是更新后的。
第二章 关系模型(relation model)
关系数据库基于关系模型,是一个或多个关系(表)组成的集合
关系(relation) = 表
元组 = 行
联系(relationship/association):是一些实体间的关联
有集合D1,D2,…D3,(Di = aij | j = 1~k)
关系r是:D1xD2…xDn的子集。(笛卡尔积的子集)
因此关系是一组n元组。
{% asset_img relation.png %}(不知道为什么这里插不了图。。TODO)关系(表)的每个属性都有一个名称
- 域:属性的取值范围(集合),null包括在每个域中
空值给数据库访问和更新带来很多困难,应避免使用空值
- 属性值:必须是原子的,即不可分割(1NF,第一范式)TODO
- 多值属性值不是原子的(电话可能有多个)
- 复合属性值不是原子的(姓名这些可拆分的)
关系模式(relation-schema):用于表示关系的结构(表头)
- 例子,Instructor-schema =(ID: string,name: string, dept_name: string, salary: int)
关系实例:用于表示一个关系的特定实例(有具体数据的表)
关系(relation)、关系模式(relation-schema)、关系实例(relation)区别:
- 变量 = 关系(表)
- 变量类型 = 关系模式(表头)
- 变量值 = 关系实例(有具体数据的表)
A1,A2…是属性
一般地:R = (A1,A2,…,An)是一个关系模式
- 例子:Instructor-schema = (ID, name, dept_name, salary)
r(R)是在关系模式R上的关系TODO P10 3:20
元组
每一行数据都是一个元组,无序但不可重复
码、键(主键、外键)
- 使K是R(属性的集合)的子集 k⊆R
- 如果K值能在一个关系(表中)中唯一地标志一个元组(一行),则K是R的超码。
- 例,{instructor-ID, instructor-name}和{instructor-ID}都是instructor的超码/超键)
- 如K是最小超码(最少属性那个超码),则K为候选码(candidate key)
- 例,上面的{instructor-ID}就是候选码,他是超码而且是最小的
主键
- 如k是一个候选码,并由用户明确定义,则K是一个主键,主键常用下划线标记。主键只能有一个。
外键
- 假设存在关系r和s:r(A,B,C),s(B,D),则在关系r上的属性B称作参照s的 外码(外键)* ,
r也称为外码依赖的参照关系,s叫做外码被参照关系。
讲人话就是:r的B字段要按照s的B字段来定制,s的B就称作为外键。
- instructor(ID,name,dept_name.salary) -参照关系
- department(dept_name,building,buget) - 被参照关系
外键的值必须在被参照关系中存在或为null,这起到约束作用。

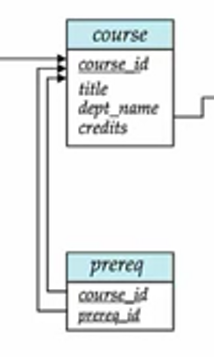
关系代数
谓词:形容客体的性质,在此处也可以是条件
此处略过。有兴趣的可以看书,我觉得这一部分可以归类的数学。
SQL概览
- SQL语言有以下几个部分:
- DDL(Data-definition Language)数据定义语言
- create tabble,alter table, drop table
- create index,drop index
- create view, drop view
- create trigger,drop trigger…
- DML(Data-manipulation Language)数据操纵语言
- select … from
- insert,delete,update
- DCL(Data-control Language)数据控制语言
- grant, revoke
- DDL(Data-definition Language)数据定义语言
- SQL语言的基本类型(注意以下为标准SQL类型,具体类型和DBMS有关,不过大致相差无几)
- char(n):固定长度的字符串,指定长度为n
- varchar(n):可变长度的字符串,用户指定最大长度n
- int:整数类型,也可用全称integer
- smallint:小整数类型
- numeric(p,d):定点数,精度由用户指定。这个数有p位数字,其中d位数字在小数点右边。
- real,double,precision: 浮点数和双精度浮点数
- float(n):精度至少位n位的浮点数
- null:每种类型都可以包含一个空值。可声明属性值不为空,禁止加入空值。
- date:日期,含年、月、日,如’2019-10-1’
- time:时间,含小时、分钟、秒,如’08:15:30’
- timestamp: 时间戳,日期 + 时间, 如’2015-3-20 08:15:30.85’
根据DBMS的不同,各自的函数名也可能不同,请自行搜索,如子字符串、时间、长度等
相同的函数
- abs()(绝对值)
- exp()(指数)
- round()(四舍五入)
- …..
SQL语句
基本模式定义(表的定义)
新建一个表
- CREATE TABLE r
(A<sub>1</sub> D<sub>1</sub>, A<sub>2</sub> D<sub>2</sub><br> ... <完整性约束1>,<br> ..., <完整性约束k>);
r是关系名,每个A是关系r模式中的一个属性名,Di是属性Ai的域
删除一个表
- DROP TABLE r;
增加表中的属性(关系中所有元组在属性上的取值为null)
- ALTER TABLE r ADD A D
删除表中的属性(此操作有许多DBMS不支持)
- ALTER TABLE r DROP A
修改表中的属性
- ALTER TABLE instructor MODIFY (ID char(10));
完整性约束
SQL支持许多不同的完整性约束
not nul, 该属性上不允许空值
primary key(A1…,An),声明表示属性A1…,An构成关系的主码(组合成一个)。主码属性必须非空且唯一,在SQL_92中无需指明not null,但在SQL_89中要指明
foreign key(A1…,An) references s(A1…,An),声明表示关系r中任意元组在属性上(A1…,An)的取值必须对应s中某元组的主码属性上的取值
check (P), P是谓词条件
例子:
1 | CREATE TABLE instructor |
- salary可能为空吗?在sql server 2000中,是可以的,在check中只要不是false即可。
SELECT语法
去除重复的元组(默认不去除为all)
- select distinct dept_name from instructor;
逻辑连词(and、or、not、between)和比较运算符(><=)
1
2
3//找出工资在9000美元和10000美元之间的教师名称
select name from instructor
where salary <= 10000 and salary >= 9000;重命名(old_name as new_name)
1
2
3
4
5//select改名
select name as instructor_name, course_id from instructor;
//from改名
select T.name from instorcor as T;字符串运算
- %:匹配任意字符串
- _: 匹配任意一个字符
- escape:定义转义字符
1
2
3
4
5
6//找任意建筑名称中包含子串‘Waston’的所有系名
select dept_name from department
where building like '%Waston%';
//转义字符的定义,这里匹配所有以"ab%cd"开头的字符串
like 'ab\%cd%' escape '\'除此之外还有其他函数,如提取子字符串、大小转换等,按需查看文档即可。
排列元组的的显示次序(order by)
1
2
3
4//默认不加为升序asc,需要指定降序可加上desc,如下
select * from instructor
order by salary desc, name asc;集合运算(请查看具体DBMS的文档)
- SQL作用在关系上的union、intersect和except对应数学集合种的并、交、差运算(注:集合运算会自动去除重复,如想保留请在后面加all)
1
2
3
4
5//找出2009年秋季开课,或者2010春季开课或两个学期都开课的所有课程
(select course_id from section where semester = 'Fall' and year = 2009)
union
(select course_id from section where semester = 'Spring' and year = 2010);基本聚集函数:输入一个为值的集合,返回单个值的函数
- 平均值:avg(输入必须为数字集)
- 最小值:min
- 最大值:max
- 总和:sum(输入必须为数字集)
- 计数:count
1
2
3
4//找出Computer Science系教师的平均工资,写as是因为返回值并没有名称
select avg(salary) as avg_salary
from instructor
where dept_name = 'Comp. Sci';分组聚集(group by)
- 在group by子句种的所有属性上取值相同的元组将会被分到一个组中
- having子句和where类似,但其对分组限定条件,而不是对元组限定条件。having子句中的谓词条件在形成分组后才起作用,因此可以使用聚集函数。
1
2
3
4
5
6
7
8//找出每个系的平均工资
select dept_name avg(salary) as avg_salary
from instructor
group by dept_name;
/*注意:任何没有出现在group by子句中的属性,如果出现在
select子句中的话,它只能出现在聚集函数内部,否则会报错。
因为你都分组了,只能按组行动,不能单独行动*/
分组
结果
1
2
3
4
5
6
7
8
9//找出教师平均工资超过42000美元的系
select dept_name avg(salary) as avg_salary
from instructor
group by dept_name
having avg(salary) > 42000;
/*注意:与select子句情况相似,任何出现在having子句中,但没有聚集的属性必须出现在group by子句中,否则会报错。
因为having是对**分组**的限定条件,你不在group里,不报你错,报谁的错。
*/空值null的说明
- null与运算符(>=<)比较都是null,如需判断属性是否为null应用is以及is not
- 除count(*)外的所有聚集函数均忽略输入集合中的空值(count会记录含null的元组)
- 子查询中的问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32select * from users
where id not int (select user_id from packages)
//此时,若 packages中某一行的user_id为null,返回结果就是空的
思考一下这里的发生了什么,假设我们的语句如下
select * from users
where id not in (1, 2, null)
这个语句会被转换为
select * from users
where id != 1 and id != 2 and id != null
/*null和什么比较都是null所以 id != null也为null ,
而任意值和null进行and运算的结果都是null,所以上面返回的结果是null。*/
我们把条件调换一下,结果就没问题了
select * from users
where id in (select user_id from packages)
例子如下:
select * from users
where id in(1, 2, null)
这条SQL转换为:
select * from users
where id = 1 or id = 2 or id = null
因为是or连接条件,所以null没问题。关于null的其他用法可以看这个博客:https://www.cnblogs.com/tv151579/p/8296540.html,写的挺好的。
嵌套子查询
子查询嵌套在where子句中,通常用于以下几个方面:
集合成员资格
- 连接词in测试元组是否是集合中的成员,集合是由select子句产生的值组合构成的,对应由not in。
1
2
3
4
5
6
7//找出在2009秋季和2010春季学期通识开课的所有课程
select distinct course_id
from section
where semester = 'Fall' and year = 2009 and
course_id in (select course_id
from section
where semester = 'Spring' and year = 2010);集合的比较
- some表示在集合中的某些元素
- all表示在集合中的所有元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14//按要求找出所有教师姓名,要求他们的工资至少比Biology系某一个老师工资高。(some)
select name
from instructor
where salary > some (select salary
from instructor
where dept_name = 'Biology');
//找出平均工资最高的系(all)
select dept_name
from instructor
group by dept_name
having avg(salary) >= all (select avg(salary)
from instructor
group by dept_name);空关系测试
- exists可测试一个子查询的结果中是否存在元组,返回true/false,与之相应的是not exists。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15//可以用not exists模拟集合的包含(超集)操作,
//如“not exists (B except A)”,
//B except A表示 B - A(差),其差若不存在则表示关系A包含关系B。
//找出在2009秋季和2010春季学期通识开课的所有课程,要求使用exists结构
select course_id
from section as S
where semester = 'Fall' and year = 2009 and
exists (select *
from section as T
where semester = 'Spring' and year = 2010 and
S.course_id = T.course_id);
//这里需要注意,在子查询中引用外部元组的变量时,都一条元组都要执行一次子查询,所以效率会比较低。重复元组存在性测试
- unique用于测试一个子查询的结果中是否存在重复元素,没有则返回true
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//注意:distince是去除重复的元组,而unique函数是检查一个子查询的结果中是否存在重复元素。(mysql似乎不支持unique函数),另外在约束条件中也有unique那个另讲。
//找出所有在2009年最多开设一次的课程
select T.course_id
from course as T
where unique (select R.course_id
from section as R
where T.course_id = R.course_id and
R.year = 2009);
//还可以这么写
select course_id
from course as C
where 1>= all(select S.course_id
from section as S
where S.year = 2009);from子句中的子查询(from后面的查询结果作为局部的视图)
1
2
3
4
5//找出所有系中工资总额最大的系
select max(tot_salary)
from (select dept_name, sum(salary)
from instructor group by dept_name)
as dept_total(dept_name, tot_salary);with子句(用于连接Local View)
- 提供定义临时关系(本地视图)的方法,该关系只在包含with子句的查询中生效
1
2
3
4
5
6
7
8
9//找出具有最大预算的系
/*定义临时关系*/
with max_budget(value) as
(select max(budget)
from department)
/*使用临时关系*/
select budget
from department, max_budget
where department.budget = max_budget.value;
修改数据库
删除:这里我们只能删除整个元组,而不能只删除某些属性的值
1
2
3
4
5
6
7
8
9//r代表关系,p代表逻辑谓词
delete from r
where p;
//删除工资低于大学平均工资的教师记录
delete from instructor
where salary < (select avg (salary)
from instructor);
//除非子查询引用了外层的关系或变量,否则子查询只执行一次插入:向关系中插入元组
1
2
3
4
5
6
7
8
9//以下两种插入形式,[]为可选项
insert into r[(c1,c2,...)]
values(e1,e2);
insert into r[(c1,c2,...)]
select e1,e2,... from ...;
//例子
inert into course
values('CS-437','DatabaseSystems','Comp',null);更新:改变整个元组的部分属性值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20//<>表示必定要。
update r
set <c1=e1,[c2=e2,...]>
[where <condition>]
//为解决update次序引发的问题,sql提供了case结构
case
when pred1 then result1
when pred2 then result2
...
when predn then resultn
else result0
end
//例子给工资超过100000的教师涨3%工资,其余教师涨5%
update instructor
set salary = case
when salary<= 10000 then salary * 1.05
else salary * 1.03
end;
总结
- SQL语句执行顺序:
- from - where - group(聚合aggregate) - having - select - order by
视图(View)
视图的定义
- 在某些情况下,让用户看到整个逻辑模型是不合适的,此时需要向用户隐藏特定的数据,所以引出了视图机制。
- 定义:通过查询定义出对用户可见的“虚关系”称为view。它在概念上包含查询结构,但并不预先计算并存储结果,仅是存储其定义本身。
视图的使用
1 | //创建视图 |
视图的更新
视图可以和常规的关系一样进行更新(增删改),但这更新是对于源关系的,例子如下。
1
2
3
4
5
6/*假定faculty是由instructor关系查询出来的的视图。*/
//下面的语句会报错,因为此插入表示instructor关系的插入,必须给出salary。
insert into faculty values('30765','Green','Music');
//解决方案:改values('30765','Green','Music',null)鉴于以上原因,下面给出视图可更新的条件

- SQL-99对视图的更新有更复杂的规则,故不讨论。
- 视图还有物化视图,即存储结果的视图,有兴趣的兄弟萌可以自行查阅。
索引
- 索引是一种数据结构,把只与查询相关的数据整合为数据结构(B+树),当用户查询时,先在索引查找到对应记录并通过其指针查找物理表中的记录。
1 | //创建索引 |